“Fine-tune” という動詞は日本語で “微調整する” と訳されている。しかし「精度を挙げる」や「仕上げる」といった訳の方が適切だと思う。いずれにせよ、AIを自分用に tuning できる時代が来た。Questetra社としても、トレーニング用データの整備を頑張ろうと考えている。
1. “Fine-Tune” という動詞
例文を作ってもらって(by GPT-4)、『Google翻訳』と『DeepL』に翻訳してもらった。
- The band spent the entire afternoon trying to fine-tune their sound before the evening performance.
- バンドは午後中ずっと、夜の演奏の前にサウンドの 微調整 に費やした。
- バンドは午後中、夜の公演を前にサウンドの 微調整 に努めた。
- As a photographer, he spent hours trying to fine-tune the lighting for his latest portrait session.
- 写真家として彼は最新のポートレートセッションのために照明を微調整するのに何時間も費やした。
- 写真家として、彼は最新のポートレート・セッションの照明を微調整するのに何時間も費やした。
- The chef continued to fine-tune the recipe, adjusting the spices until he was completely satisfied with the taste.
- シェフは味に完全に満足するまでスパイスを調整しながらレシピを 微調整 し続けた。
- シェフはレシピの 微調整 を続け、味に完全に満足するまでスパイスを調整した。
- The team of engineers worked diligently to fine-tune the robot’s movements, ensuring precision and efficiency.
- エンジニアのチームはロボットの動きを 微調整 するために熱心に働き、精度と効率を確保した。
- エンジニアのチームは、ロボットの動きを 微調整 し精度と効率を確保するために熱心に取り組んだ。
どうやら “微調整” と訳すヨウダ。
たしかに、”sound” や “lighting” や “recipe” や “robot’s movements” であれば 微調整 して頂いてもイッコーに構わない。「イイ感じ(fine)に、調整(tune)する」 という複合語としてのニュアンスにも近い。
2. AI の “微調整” ?

しかし「AIを微調整する」という表現は、日本語としては理解しづらい。(と思う)
というか「現場の誤解」を招きそうな気がする! 延いては「日本のDX」のアシカセになるやも知れない!! (←などと書きつつも、すでに何度も読み聞きして慣れてしまいつつある…)
つまるところ、(かなりの主観なのだが)、 “微調整” などという甘っちょろい言葉(?)では “変化した感” がしない のだ。もっともっと “変化させたぜ感” を表現してほしい のだ。(過去に縛られてはイケナイ!)
#「微調整された人間」ではない。それ即ち「強化人間」なのだ。的な。。。 実際、(その動機は様々だろうが)、「精密調整する」と訳されたり、カタカナで「ファインチューニングする」と書かれたりする例もある。
3. ファインチューニングとは?
ちなみにAI分野における専門用語 “Fine-Tune” は「再トレーニングの行為」を表現している。
具体的に言えば「Pre-training 済みモデル」(Pre-trained Model)に対して、更に Training を施すのだ。そうすると、Fine-Tuned MODEL が出来上がる!
#ウチのCTO曰く、「新卒社会人」(GPT-4)に「業務知識をに教え込むこと」。 (「ベテラン社員」が出来上がる?)
…でアレバ!…だ。「精度を挙げる」とか、「(バキバキに)仕上げる」といった “変化した感” のある訳し方をして欲しいのだ。 (わー、やっぱり、ただの主観だなぁ)
⇒ 強化モデル、特化モデル、精緻モデル、細密モデル、博識モデル、精進モデル、修練モデル、鍛錬モデル!

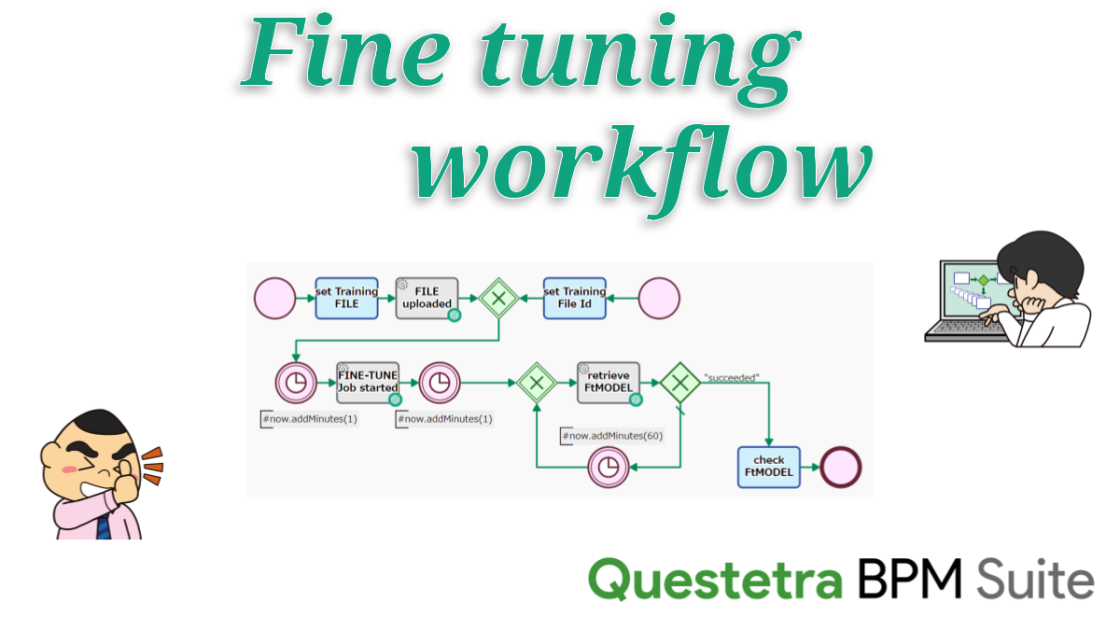
4. ちなみに “微調整” のコストは?
「お金」の面ではケッコー軽微だが、「時間」の面ではメンドウになるかもしれない。現時点(202307)においても、”Pending ステータス” はソコソコ長い。(それだけに “微” だと思えない)(「イイ感ジニ調整シテイル」のなら待てる!?!)
▼4行JSONLの場合
2023-07-26T08:00:26.000Z info Created fine-tune: ft-pYZvA9NP5ddBbe6ud6Mexjne
2023-07-26T11:48:44.000Z info Fine-tune costs $0.01
2023-07-26T11:48:44.000Z info Fine-tune enqueued. Queue number: 0
2023-07-26T12:00:40.000Z info Fine-tune is in the queue. Queue number: 3
2023-07-26T12:12:46.000Z info Fine-tune is in the queue. Queue number: 2
2023-07-26T12:13:18.000Z info Fine-tune is in the queue. Queue number: 1
2023-07-26T12:13:31.000Z info Fine-tune is in the queue. Queue number: 0
2023-07-26T12:14:44.000Z info Fine-tune started
2023-07-26T12:15:43.000Z info Completed epoch 1/4
2023-07-26T12:15:44.000Z info Completed epoch 2/4
2023-07-26T12:15:45.000Z info Completed epoch 3/4
2023-07-26T12:15:46.000Z info Completed epoch 4/4
2023-07-26T12:16:05.000Z info Uploaded model: curie:ft-questetra-2023-07-26-12-16-05
2023-07-26T12:16:06.000Z info Uploaded result file: file-526WjgJtypVc9A2gcR1BWh9m
2023-07-26T12:16:06.000Z info Fine-tune succeeded▼16行JSONLの場合
2023-07-26T06:57:15.000Z info Created fine-tune: ft-lN1WPLOp8rtoalbMG5Nctc0T
2023-07-26T10:19:09.000Z info Fine-tune costs $0.04
2023-07-26T10:19:09.000Z info Fine-tune enqueued. Queue number: 1
2023-07-26T10:21:50.000Z info Fine-tune is in the queue. Queue number: 0
2023-07-26T10:22:11.000Z info Fine-tune started
2023-07-26T10:23:16.000Z info Completed epoch 1/4
2023-07-26T10:23:19.000Z info Completed epoch 2/4
2023-07-26T10:23:23.000Z info Completed epoch 3/4
2023-07-26T10:23:26.000Z info Completed epoch 4/4
2023-07-26T10:23:43.000Z info Uploaded model: curie:ft-questetra-2023-07-26-10-23-43
2023-07-26T10:23:44.000Z info Uploaded result file: file-tOsEJP0WH3BTcLxyBMz1aLX2
2023-07-26T10:23:44.000Z info Fine-tune succeeded※ 実業務で使えそうな JSONL ファイル〔1000行以上〕は、まだ試していない。 (←ていうかナイ)
5. 各社がファインチューニングする時代
OpenAI 社のアナウンスを素直に読めば、2023年中に、各社それぞれが “GPT-4” をチューニングできるようになる。(バキバキに!?!)
つまるところ、もはや「再トレーニング用のデータを整備し続ける」は多くの会社にとって必要不可欠な作業なのだ。
では、トレーニング用のデータをどう整備すべきか?
う~む。それは各社それぞれで工夫するしかない。業種業態によっても大きく異なる。ただ、一つ言えることは「その整備作業自体もAIに手伝ってもらうべき」だ。Questetra社もゼッサン模索中である。(がんばるぞー)
https://platform.openai.com/docs/guides/fine-tuning
- On July 6, 2023, we announced the deprecation of ada, babbage, curie and davinci models. These models, including fine-tuned versions, will be turned off on January 4, 2024. We are actively working on enabling fine-tuning for upgraded base GPT-3 models as well as GPT-3.5 Turbo and GPT-4, we recommend waiting for those new options to be available rather than fine-tuning based off of the soon to be deprecated models.
- 2023 年 7 月 6 日に、ada、babbage、curie、davinci モデルの廃止を発表しました。 微調整バージョンを含むこれらのモデルは、2024 年 1 月 4 日にオフになります。私たちは、アップグレードされたベース GPT-3 モデル、GPT-3.5 Turbo および GPT-4 の微調整を可能にすることに積極的に取り組んでいます。間もなく非推奨になるモデルに基づいて微調整するのではなく、これらの新しいオプションが利用可能になるまで待つことをお勧めします。
- 2023年7月6日、アダ、バベッジ、キュリー、ダヴィンチの各モデルの非推奨化を発表しました。これらのモデルは、ファインチューニング・バージョンを含め、2024年1月4日に廃止されます。GPT-3、GPT-3.5ターボ、GPT-4のアップグレードモデルのファインチューニングを可能にするために積極的に取り組んでいます。
https://openai.com/blog/gpt-4-api-general-availability
- GPT-4 is our most capable model. Millions of developers have requested access to the GPT-4 API since March, and the range of innovative products leveraging GPT-4 is growing every day. Today all existing API developers with a history of successful payments can access the GPT-4 API with 8K context. We plan to open up access to new developers by the end of this month, and then start raising rate-limits after that depending on compute availability. Based on the stability and readiness of these models for production-scale use, we are also making the GPT-3.5 Turbo, DALL・E and Whisper APIs generally available. We are working on safely enabling fine-tuning for GPT-4 and GPT-3.5 Turbo and expect this feature to be available later this year.
- GPT-4 は当社の最も高性能なモデルです。 3 月以来、何百万もの開発者が GPT-4 API へのアクセスをリクエストしており、GPT-4 を活用した革新的な製品の範囲は日々増加しています。 現在、成功した支払い履歴を持つすべての既存の API 開発者は、8K コンテキストを備えた GPT-4 API にアクセスできます。 今月末までに新しい開発者にアクセスを開放し、その後はコンピューティングの可用性に応じてレート制限の引き上げを開始する予定です。これらのモデルの安定性と実稼働規模での使用の準備に基づいて、GPT-3.5 Turbo、DALL・E、および Whisper API も一般公開しています。 私たちは GPT-4 および GPT-3.5 Turbo の微調整を安全に有効にすることに取り組んでおり、この機能は今年後半に利用可能になる予定です。
- GPT-4は当社の最も高性能なモデルです。3月以来、何百万人もの開発者がGPT-4 APIへのアクセスを要求しており、GPT-4を活用した革新的な製品の範囲は日々拡大しています。GPT-4を活用した革新的な製品の種類は日々増えています。現在、支払い実績のあるすべての既存API開発者は、8KコンテキストでGPT-4 APIにアクセスできます。今月末までには新しい開発者にもアクセスを開放し、その後はコンピュート利用可能性に応じてレートリミットの引き上げを開始する予定です。これらのモデルの安定性とプロダクション・スケールの使用への準備に基づき、GPT-3.5 Turbo、DALL・E、Whisper APIも一般的に利用できるようにしています。我々は、GPT-4とGPT-3.5 Turboの微調整を安全に行えるように取り組んでおり、この機能は今年後半に利用可能になる予定です。
PS
付随して “モデル” の適訳はナニ? という議論もある。
典型的には “模型” なんだろう。。。 が、もはや訳さない方がイイ。
そもそも、“モデル” は概念的に「簡単化した図式数式」であり「理想的なスタイル」だ。(対象を “簡略化” し、”本質” を表している)
- ワークフロー定義(業務プロセス定義)のコト: “プロセスモデル”
- データ格納方法を定めたソフトウェア開発文書: “データモデル”
- 企業が利潤を得る構造(誰が何に対し支払う): “ビジネスモデル”
- 彫刻や写真の題材提供のためにポーズをとる人: “モデル”
したがって “大規模言語モデル” (LLM / Large Language Model)も「言語模型」でしかない。しかしながら他方、(その中身が “模型” であるかどうかはサテオキ)、多くの人は彼らの出力に「知性らしきもの」を感じている。
つまるところ “モデル” は文脈によって「人工知能」(Artificial Intelligence)と訳してしまえば良い。(と思う)(暴)〔鍛錬済み人工知能〕
と言いつつも、(ウシロメタサがあるので/ハバカラレルので)、日頃は “MODEL” と表記するようにしている。(←小市民)〔鍛錬済みMODEL〕





